Cache(캐시)
Memory Hierarchy
| 메모리 유형 | 포함된 메모리 종류 |
| Inboard Memory | - Registers(레지스터) - Cache(캐시) - Main Memory(주기억장치) |
| Outboard Storage | - Magnetic Dist - CD-ROM - CD-RW - DVD-RAM - Blu-Ray |
| Off-line Storage | - Magnetic Tape |
메모리 계층 구조(Memory Hierarchy)는 컴퓨터에서 사용하는 메모리를 계층 구조로 나눈 것이다. 일반적으로 성능(속도)을 기준으로 나누는데 CPU와 가까운 메모리일 수록 비싸고 빠르다.
Locality of Reference
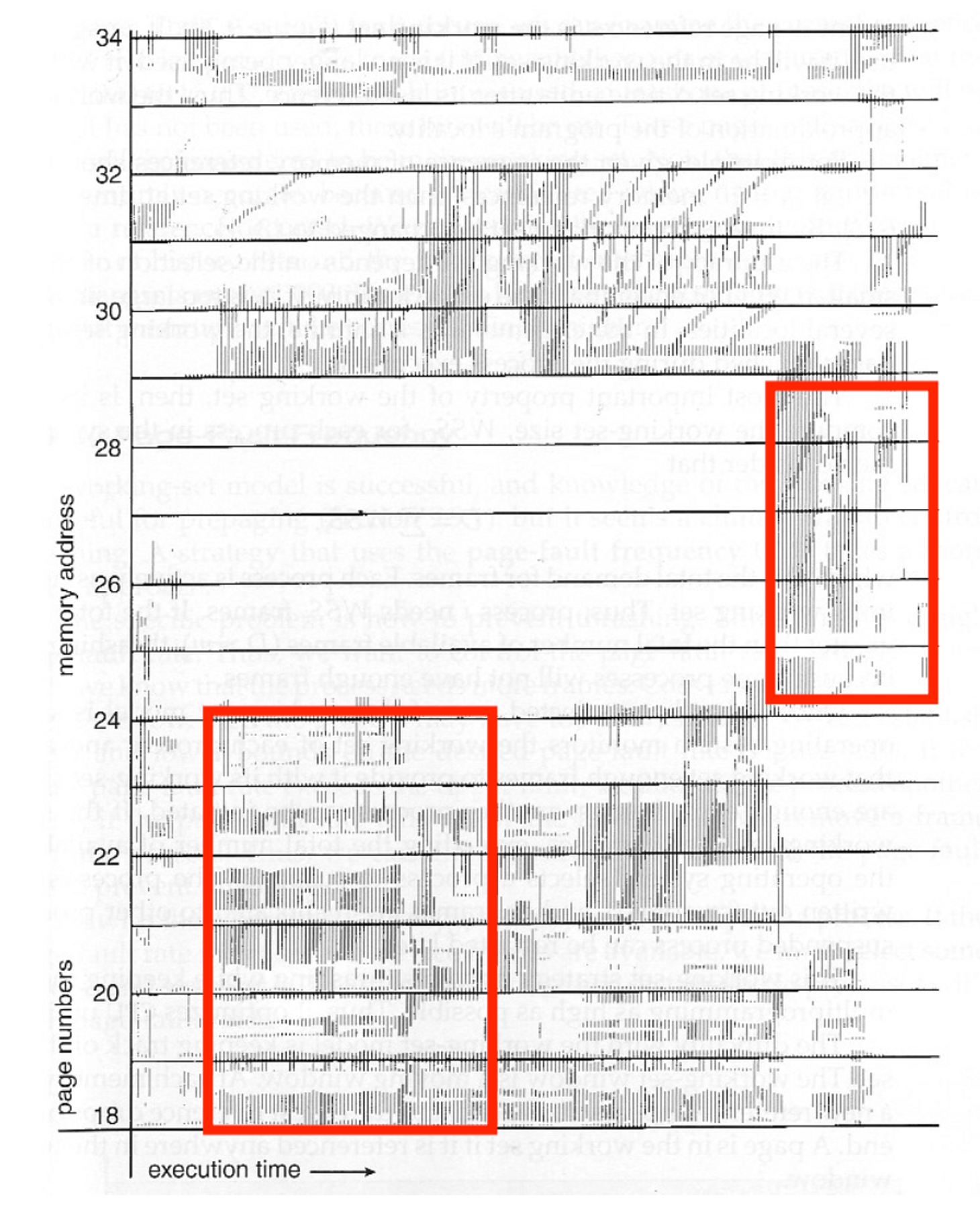
참조 지역성의 원리(Locality of Reference)는 CPU가 메모리에 접근할 때 경향성을 띄는데, 이러한 경향을 바탕으로 만들어진 원리다.
위 그래프의 가로축은 시간이고 세로축은 활성화되는 메모리 지역이다. 그림에서 볼 수 있듯이 시간에 따라, 프로그램의 진행 단계에 따라 주로 사용하는 메모리의 지역성이 존재함을 볼 수 있다.
이러한 경향성을 파악하여 주로 사용할 것 같은 메모리의 정보를 예측하고, 접근이 빠른 저장장치에 담아두어 전체적인 성능을 향상해보자는 아이디어에서 나온 것이 캐시 메모리이다.
Cache Memory

기본적인 캐시 메모리는 위와 같이 CPU와 Main Memory 사이에 위치한다. 때문에 캐시 메모리를 사용할 때는 주기억장치에 접근하는 시간보다 더 적은 시간이 소요된다.

위와 같이 캐시 메모리를 여러 개 둘 수도 있다. 이 때는 각 캐시의 레벨을 나누어 구분한다. 캐시 레벨이 낮을 수록 CPU와 가까이 있기 때문에 빠르다. (메모리 속도: L1 > L2 > L3 > ...)

앞서 캐시 메모리는 CPU와 가까이 있기 때문에 접근이 빠른 저장장치라고 했다. 이를 쉽게 설명하면 다음과 같다.
<메인 메모리로부터 캐시 메모리에 데이터를 가져오는 경우>
음식점(CPU)에서 음식을 팔기 위해서는 창고(Main Memory)로 부터 재료(Data)들을 가져와야 한다.
그러나 물건이 부족할 때마다 창고까지 가서 재료들을 가져오기에는 번거롭기 때문에, 많이 필요할 것으로 예상되는 재료를 수레(Cache Memory)에 담아서 효율성을 높이려고 한다. 많이 필요할 것으로 예상되는 재료는 어느정도 경향성(참조 지역성의 원리)을 갖고 있기 때문에 예측해볼 수 있다.
이때 수레 내부에는 재료들을 효율적으로 담기 위해 제작된 통(Block)이 있고, 창고로부터 수레에 재료를 담을 때는 이 통단위로 가져와야 한다.
그런데 만약 어떤 단체 손님들이 김치찌개를 많이 주문했다고 했을 때는 수레에 김치를 많이 담아야 한다. 이 때 김치들을 통(Block)에 무작정 담게 되면, 밑반찬으로 쓸 김치와 김치찌개에 쓸 김치가 섞일 위험이 있다. 이때 통마다 그 용도에 대한 설명(Tag)을 적어두어 구분할 수 있도록 한다.
<컴퓨터가 데이터를 필요로 하는 경우>
이제 요리사가 요리를 해야 하는 상황이라고 가정하자. 먼저 요리사는 수레(Cache Memory)로부터 필요한 재료(Data)가 있는지 확인할 것이다.
이때 재료들은 수레에 맞게 제작된 통(Block)에 담겨있기 때문에 원하는 재료가 담겨있는지 찾는 과정이 필요하다. 이때 통에 적혀있는 설명(Tag)을 통해 확인한다.
만약 수레에 원하는 재료가 모두 있다면 바로 요리를 진행한다. 그러나 원하는 재료가 없다면 창고(Main Memory)로 가서 수레(Cache Memory)에 재료(Data)를 담고 음식점(CPU)에 도착한 다음 요리를 진행한다.
Mapping Function
메인 메모리와 캐시 메모리 사이에 데이터를 주고 받는 방식을 Mapping(사상)이라고 한다. 대표적인 Mapping 방식에는 다음과 같이 있다.
Direct Mapping
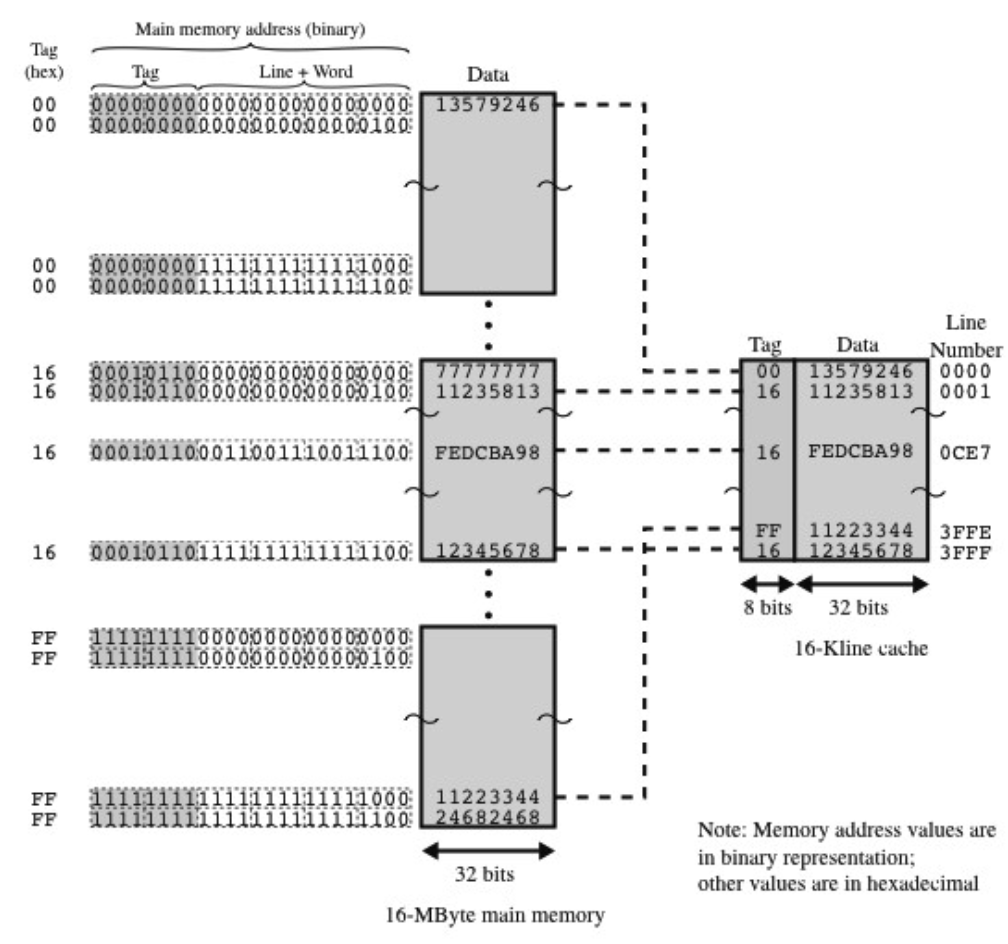
직접 사상 방식은 메인 메모리 주소로부터 Tag, Line, Word 정보를 받아와 캐시 메모리 내에 저장될 위치를 결정하는 방식이다.
tag는 캐시 메모리에 저장된 데이터가 메인 메모리의 어떤 주소에서 가져왔는지를 구분하기 위한 정보이고, Line은 캐시 메모리 내 몇 번째 라인에 저장할지를 구분하기 위한 정보이다. 마지막으로 word는 사용할 데이터 조각이 담기는 공간이다.
이러한 직접 사상 방식의 특징은 메인 메모리로부터 캐시 메모리로 데이터를 가져올 때 이미 Line 정보를 통해 저장될 공간이 정해졌다는 점이다.
이로 인해 캐시 메모리가 가득 찼을 때 내보낼 데이터를 정하는 알고리즘을 따로 구현할 필요가 없다.
그리고 캐시 메모리에 원하는 데이터가 있는지를 확인하기 위해 간단히 tag와 line 정보만 확인하면 된다.
그러나 직접 사상 방식의 문제점은 메인 메모리로부터 캐시 메모리로 데이터를 가져올 때 저장될 공간이 이미 정해져있기 때문에, 캐시 메모리에 빈 공간이 있음에도 불구하고 지정된 공간에 다른 데이터가 저장되어 있다면 먼저 저장된 데이터를 내보내야 한다. 이때 내보낸 데이터가 자주 사용될 것으로 예측되는 데이터라고 하더라도 캐시 메모리 내에 저장될 공간이 정해져 있기 때문에 내보내져야 한다. 때문에 불필요한 교체 작업으로 인한 성능 저하 문제가 발생할 수 있다.
Associative Mapping

연관 사상 방식은 메인 메모리 주소로부터 Tag, Word 정보를 받아와 캐시 메모리에 저장될 위치를 결정하는 방식이다. 캐시 메모리에 저장될 때 저장될 위치를 따로 정의할 필요가 없기 때문에 Line 정보가 필요하지 않다.
이러한 연관 사상 방식은 메인 메모리로부터 캐시 메모리에 데이터를 가져올 때 저장될 공간을 미리 정하지 않아서 캐시 메모리 공간이 비어있는 한 아무런 제약 없이, 교체 작업 없이 저장할 수 있다. 이로 인해 이론상 캐시 메모리의 이용 효율이 좋아진다.
그러나 캐시 메모리에 원하는 데이터가 있는지 확인하기 위해서는 캐시 메모리 전체를 살펴보며 tag를 일일이 대응하는 과정을 거쳐야 한다. 그리고 캐시 메모리가 가득 차게 되면 어떤 데이터를 먼저 내보낼지에 대한 알고리즘을 구현할 필요가 있다.
K-Way Set Associative Mapping

집합 연관 사상 방식은 메모리 주소로부터 Tag, Set, Word 정보를 받아와 캐시 메모리에 저장될 위치를 결정하는 방식이다. 이 방식의 특징은 캐시 메모리를 K개 두었다는 점이다.
이 방식은 캐시 메모리가 여러 개 있어서 직접 사상 방식에서 문제가 되었던 라인 중복 문제를 해결할 수 있다.
또한 강의에서는 Set 정보를 Line 정보와 동일하게 취급하였기 때문에, 단순히 직접 사상 방식을 여러 세트 두었다고 볼 수 있다고 한다. 따라서 간단하게 구현이 가능하다는 장점이 있다.
번외로, 4-Way 이상부터는 성능이 비슷하다는 경향이 있다.
Replacement Algorithm
교체 알고리즘은 앞서 설명한 연관 사상 방식(Associative Mapping)에서 사용되는 알고리즘이다. 이 방식은 캐시 메모리에 데이터를 저장할 때 저장할 공간에 대한 정해두지 않고 빈 공간이 있을 때마다 저장하는 방식을 사용했기 때문에 캐시 메모리가 가득 찼을 때 어떤 데이터를 내보낼지를 정하는 알고리즘이 필요하다.
이때 필요한 교체 알고리즘의 종류는 다음과 같다.
| 교체 알고리즘 종류 | 설명 |
| Least Recently Used(LRU) | 가장 오랜 기간 참조되지 않은 캐시를 내보내는 방식으로 가장 효과적이고 상용화된 방식으로 알려져 있다. 이 방식을 구현하기 위해서는 캐시 별로 최근에 사용된 시간과 현재 시간에 대한 정보가 필요하다. |
| First In First Out(FIFO) | 캐시 메모리에 들어온 순서대로 내보내는 방식이다. 이 방식을 구현하기 위해서는 캐시 별로 캐시 메모리에 들어온 시간에 대한 정보가 필요하다. |
| Least Frequently Used(LFU) | 가장 적은 횟수로 참조된 캐시를 먼저 내보내는 방식이다. 이 방식을 구현하기 위해서는 캐시 별로 캐시 히트된 횟수에 대한 정보가 필요하다. |
Write Policy
Write Policy는 쓰기 작업에 관한 개념이다. 데이터를 불러와 읽는 작업은 단순히 메인 메모리로부터 캐시로 데이터를 불러와 읽으면 된다. 그러나 데이터를 쓰는 작업은 결과를 캐시에 있는 데이터에 적용할지, 메인 메모리에 있는 데이터에 적용할지 정해야 한다.
이를 정하는 방식의 종류는 다음과 같다.
| Write Policy 종류 | 설명 |
| Write Through | - 메인 메모리와 캐시 메모리에 동시에 쓰는 방식이다. - 데이터의 수정 사항을 확실하게 적용하여 시스템의 일관성을 유지할 수 있다. - 메인 메모리에 쓰는 속도가 많이 느리기 때문에 전체적인 속도가 늦어질 수 있다. |
| Write Back | - 우선 캐시 메모리에만 쓰고 메인 메모리에는 나중에 적용하는 방식이다. - 데이터가 메인 메모리로 이동될 때 캐시 메모리에 저장된 데이터를 이동시킨다. - 메인 메모리에 접근하는 빈도가 적기 때문에 시스템 성능을 향상할 수 있다. |
'대학교 공부 > 컴퓨터시스템 (2023)' 카테고리의 다른 글
| 5주차 - MU0, Parallelism(파이프라이닝, 스칼라) (0) | 2023.04.10 |
|---|---|
| 4주차 - Instruction Execution Unit, 주소 지정 방식, Hard wired & Micro programming (0) | 2023.04.10 |
| 3주차 - 최상위 관점에서의 CPU요소, 폰노이만&하버드 구조, CISC&RISC (0) | 2023.03.25 |
| 2주차 - 컴퓨터 시스템 설명 (0) | 2023.03.17 |