EU(The Instruction Execution Unit)
3주차 - 최상위 관점에서의 CPU요소, 폰노이만&하버드 구조, CISC&RISC
최상위 관점에서의 CPU요소 종류 설명 PC 앞으로 실행할 명령어의 주소 저장 IR 지금 수행할 명령어 저장 MAR 메모리로부터 데이터를 읽고 쓸 때 필요한 주소 저장 MBR 메모리로부터 데이터를 읽고
jschan0911.tistory.com
이전에 최상위 관점에서의 CPU 구조를 설명할 때, EU를 ALU의 상위 개념으로 언급한 적이 있다. EU의 내부 구조를 살펴보면 다음과 같다.
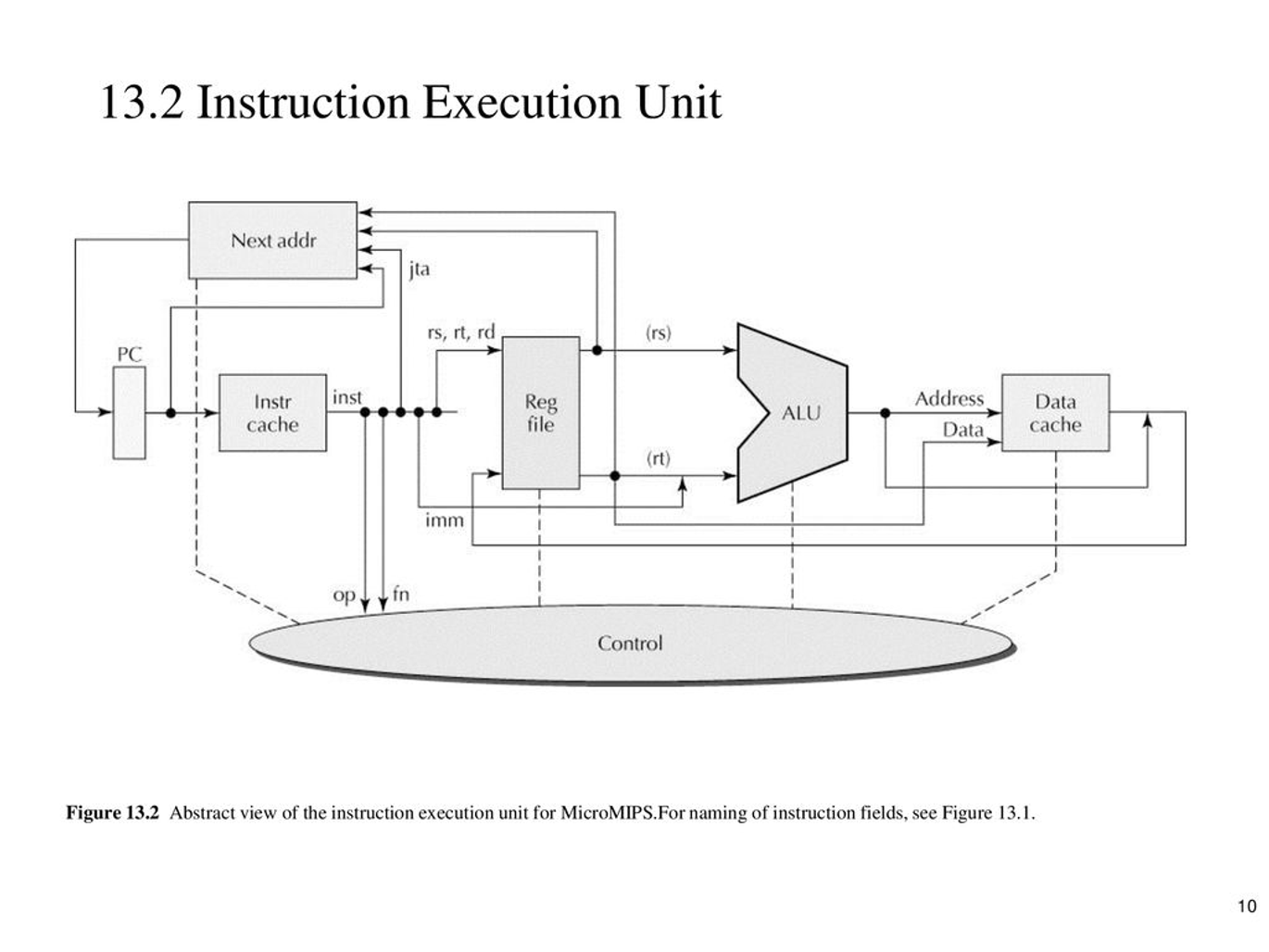
| 부품 | 역할 |
| Next addr | 현재 실행 중인 명령어의 다음으로 실행될 명령어의 주소를 계산하는 회로 |
| PC | 현재 실행 중인 명령어의 주소를 저장하는 레지스터 |
| Instr cache | 메모리로부터 명령어를 불러와 IR에서 사용하기 전까지 임시로 저장하는 캐시 메모리 |
| Reg file | 데이터를 저장하는 다수의 레지스터를 담고 있는 메모리 요소 |
| ALU | 산술 및 논리 연산을 수행하는 회로 |
| Data cache | 메모리로부터 데이터를 불러와 임시로 저장하는 캐시 메모리 |
| Control | 명령어의 실행을 제어하는 회로 명령어를 해독하고 분기 명령어를 만났을 때 다음으로 실행될 명령어의 주소를 계산 |
사진 속 각 부품에 대한 설명은 위와 같다.
추가적으로, 공부하면서 개인적으로 헷갈렸던 내용에 대해 정리해보았다.
Next addr vs ALU vs Control
다음으로 실행될 명령어의 주소를 계산할 때, PC에 저장된 값을 ALU에서 +1 연산한다고도 했는데, 그렇다면 Next addr에서 하는 것과는 뭐가 다른지에 대해서 궁금했다. 또한 분기 명령어를 만났을 때 Next addr과 Control 둘 다 그에 따른 다음 명령어 주소 계산을 수행한다고 했는데 이 둘의 방식이 같은지, 다른지를 알고 싶었다.
일반적으로 ALU가 다음 명령어 주소를 계산하기 위해 +1 씩 하는 연산을 한다면, Next addr은 현재 실행 중인 명령어의 길이를 더하는 방식으로 다음 명령어의 주소를 계산한다고 한다. 만약 분기가 발생했을 때는 Next addr에서는 그에 따른 명령어 주소의 계산이 가능하다고 한다.
Next addr과 Control 모두 분기 명령어에 따른 다음 명령어 주소 계산 역할을 수행할 수 있는 건 맞다. 다만 그 방식에서의 차이는 존재한다. Next addr은 다음 명령어 주소 계산에만 특화된 하드웨어로, 위에서 언급한 대로 현재 실행 중인 명령어의 길이를 고려하여 PC값에 더하는 방식으로 계산한다. Control은 분기 명령어의 조건 평가, 분기 주소 계산 등 다양한 명령어 실행 제어 역할을 수행한다. 따라서 보다 복잡한 명령어 실행을 제어할 수 있다고 한다.
Reg file vs ACC
메모리로부터 데이터를 불러와 임시로 저장한다는 의미에서 Reg file과 ACC(Accumulator)의 관계가 어떤지 궁금했다.
ACC는 연산을 위한 데이터만을 임시로 저장하는 레지스터이고, Reg file은 ACC를 포함한 여러 레지스터의 모음으로 상위 개념인 셈이다. 또한 Reg file은 ACC와 달리 레지스터 간 데이터 이동 시에도 사용된다는 점에서 차이가 있다.
Addressing Mode(주소 지정 방식)
Direct Addressing

직접 주소 지정 방식을 그림으로 나타내면 위와 같다.
왼쪽에 있는 네모칸이 연산코드(OP code)와 A(오퍼랜드, 피연산자)로 이루어진 명령어이다. 오른쪽에 있는 네모칸은 기억장치(메모리)이다. 이 사이를 이어주는 것은 EA(Effective Address)로 실제 메모리 주소를 나타내는 값이다.
즉, 이 방식은 데이터가 존재하는 실제 메모리 주소를 오퍼랜드에 직접 저장하는 방식이다.
직접 주소 지정 방식은 명령어에 메모리 주소가 직접 저장되어 있어서 메모리 접근 속도가 빠르고 간단하다는 장점이 있다. 그러나, 명령어의 크기가 커지고 저장 효율이 떨어지며, 저장 공간의 수정이 필요할 경우 프로그램 전체를 수정해야 한다는 단점이 있다.
Register Addressing

레지스터 주소 지정 방식을 그림으로 나타내면 위와 같다.
직접 주소 지정 방식과 대체로 비슷하지만 데이터가 메모리가 아닌 레지스터에 존재한다는 점에서 차이가 있다. 때문에 오퍼랜드에 실제 메모리 주소 대신 레지스터 번호가 저장된다.
레지스터 주소 지정 방식은 명령어에 레지스터 번호를 저장하기 때문에 명령어의 길이가 상대적으로 짧다. 그리고 데이터가 레지스터에 저장되어 있으므로 데이터 접근 속도가 빠르다. 하지만, 레지스터의 수가 제한적이라는 한계가 있다.
Register Indirect Addressing

레지스터 간접 주소 지정 방식을 그림으로 나타내면 위와 같다.
명령어 부분은 레지스터 주소 지정 방식과 비슷하다. 그러나 명령어에 저장된 레지스터 번호를 따라 레지스터에 접근하면, 데이터가 저장되어있지 않고 데이터가 저장된 실제 메모리 주소를 알기 위해 필요한 정보가 저장되어 있다. 그리고 이 정보와 명령어의 나머지 오퍼랜드 부분을 연산하여 실제 메모리 주소를 알아낸다
즉, 명령어를 통해 데이터에 접근하기 위해서 다음과 같은 과정을 거친다.
- 명령어의 오퍼랜드 부분을 해석
- 오퍼랜드에 적힌 레지스터 번호를 따라 레지스터에 접근
- 레지스터에 적힌 정보와 명령어의 오퍼랜드 정보를 이용해 메모리 주소를 계산
- 해당 메모리 주소에 저장된 데이터에 접근 완료
이 방식은 레지스터에 저장된 주소가 변경될 때마다 코드 전체를 수정할 필요가 없다는 장점이 있다. 그러나, 주소 지정에 필요한 명령어의 길이가 더 길어지기 때문에 상대적으로 많은 메모리 공간이 필요할 수 있다.
Memory Indirect Addressing

간접 주소 지정 방식을 그림으로 나타내면 위와 같다.
명령어 부분은 '직접 주소 지정 방식'과 동일하게 연산코드와 메모리 주소가 저장된 오퍼랜드로 구성되어 있다. 그러나 오퍼랜드에 저장된 메모리 주소에 접근했을 때 바로 데이터가 저장되어 있는 게 아니라, 데이터가 저장된 또다른 실제 메모리 주소가 저장되어 있다.
즉, 오퍼랜드에 저장된 메모리 주소를 따라 접근한 곳에는 실제 데이터가 있는 주소를 가리키는 포인터가 있는 것이다.
이 방식을 사용하면 특정 주소가 바뀌더라도 프로그램 전체가 바뀔 필요 없이 포인터가 가리키는 주소만 변경하면 되므로 유연하고 동적인 데이터 구조를 설계할 수 있다. 그러나, 메모리 접근을 두 번 하기 때문에 실행 시간이 오래 걸리고 주소 지정에 필요한 명령어의 길이가 더 길어지기 때문에 상대적으로 많은 메모리 공간이 필요할 수 있다.
Immediate Addressing

즉시 주소 지정 방식을 그림으로 나타내면 위와 같다.
명령어의 오퍼랜드 필드에 데이터를 직접 저장하는 방식이다.
이 방식은 데이터를 레지스터나 메모리 같은 기억장치에 저장하지 않았기 때문에 저장장치 참조 작업을 수행하지 않아 빠른 연산을 가능하게 한다. 그러나, 데이터가 제한된 명령어 길이 안에 저장되어야 하기 때문에 데이터의 크기가 상대적으로 작아야 하고, 데이터를 수정할 일이 생기면 프로그램 자체를 수정해야 한다.
Hard-wired&Micro programming
| 종류 | 설명 |
| Hard-wired | - 고정된 제어 로직을 사용하여 제어 신호를 생성하는 방식 - 하드웨어가 간단하고 빠르게 동작 가능 - 추후에 변경이 불가능 - 명령어가 작고 단순한 RISC를 사용해 간단한 CPU 제작 가능 |
| Micro programming | - 소프트웨어를 통해 제어 유닛 동작을 구현하는 방식 - 추후에 변경 가능 - 명령어가 많고 복잡한 CISC를 사용해 복잡한 CPU 제작 가능 |
컴퓨터 제어 유닛을 구현하는 방식에는 위와 같이 두 가지 방식이 있다.
'대학교 공부 > 컴퓨터시스템 (2023)' 카테고리의 다른 글
| 6주차 - Cache(캐시), Mapping Function(사상 방식), Replacement Algorithms(교체 알고리즘), Write Policy (0) | 2023.04.10 |
|---|---|
| 5주차 - MU0, Parallelism(파이프라이닝, 스칼라) (0) | 2023.04.10 |
| 3주차 - 최상위 관점에서의 CPU요소, 폰노이만&하버드 구조, CISC&RISC (0) | 2023.03.25 |
| 2주차 - 컴퓨터 시스템 설명 (0) | 2023.03.17 |