MU0를 이용한 CPU 동작 설명
MU0는 Manchester Univ.에서 고안한 가상의 CPU 구조이다. 매우 간단한 구조를 가지고 있어서 CPU의 동작을 설명하기에 용이한 구조다.
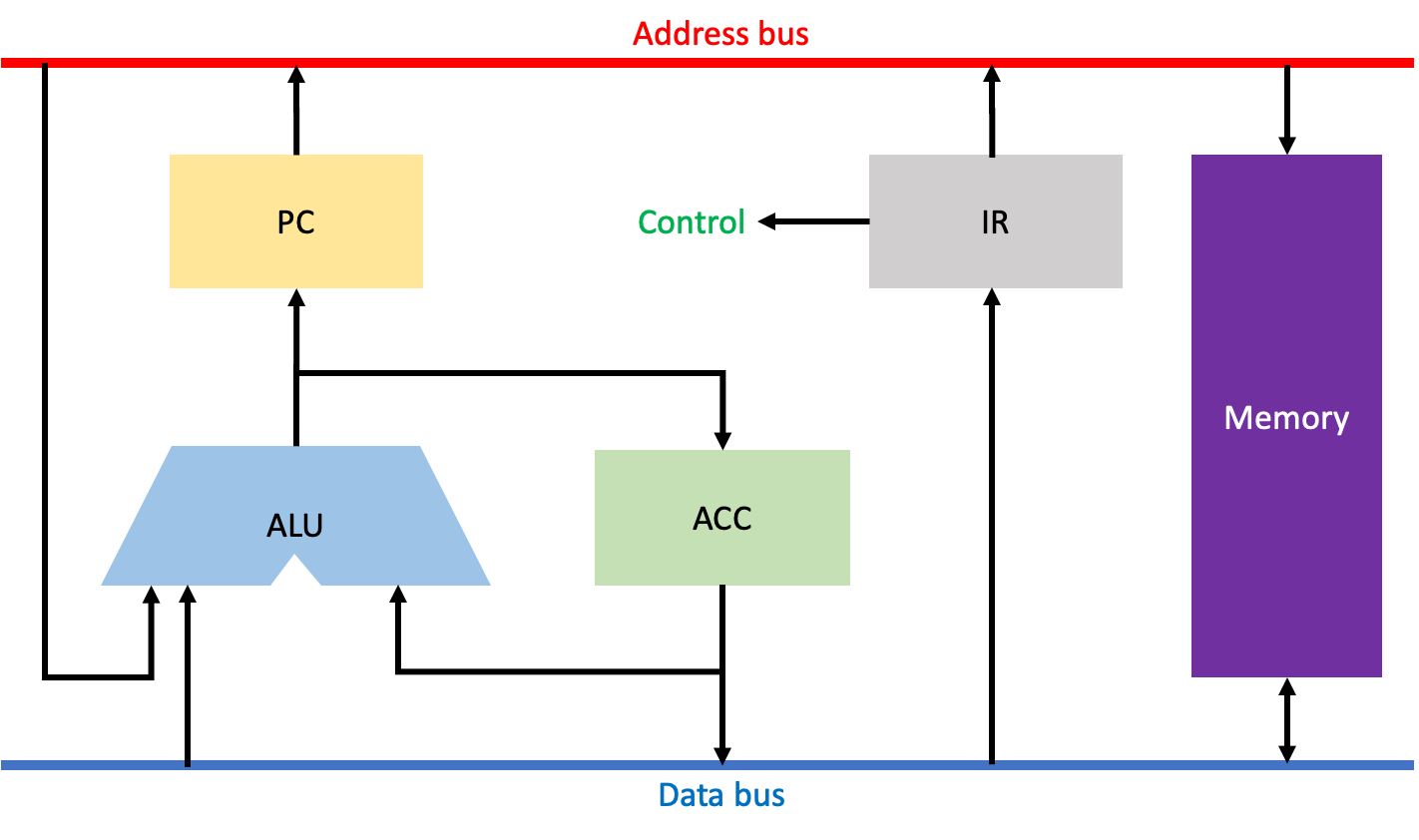
MU0는 위와 같은 구조를 가지고 있다. PC(Program Counter: 다음으로 실행할 명령어의 주소를 저장), ACC(Accumulator: 메모리로부터 불러온 데이터를 저장), ALU(Arithmatic and Logical Unit: 연산을 담당), IR(Instruction Register, 메모리로부터 불러온 명령어를 저장), 메모리로 구성되어 있고, 주소버스와 데이터버스, 컨트롤유닛도 볼 수 있다.

MU0에서 사용하는 명령어 포멧은 위와 같다. 앞 4비트는 OP코드를, 뒤 12비트는 메모리 주소를 저장하는 직접 주소 지정 방식의 16비트 RISC 포멧이다.
| OP코드 | 명령어 | 설명 |
| 0000 | LDA S | ACC <- M[S] |
| 0001 | STO S | M[S] <- ACC |
| 0010 | ADD S | ACC <- ACC + M[S] |
| 0011 | SUB S | ACC <- ACC - M[S] |
| 0100 | JMP S | PC <- S |
| 0101 | JGE S | PS <- S, if ACC >= 0 |
| 0110 | JNE S | PC <- S, if ACC != 0 |
| 0111 | STP | stop |
MU0에서 사용하는 명령어 집합은 위와 같이 있다. 각각 자세히 설명하면 다음과 같다.
- LDA(Load): 메모리 주소 S에 있는 데이터를 ACC에 저장한다.
- STO(Store): ACC에 있는 데이터를 메모리 주소 S에 저장한다.
- ADD(Addition): ACC에 있는 데이터와 메모리 주소 S에 있는 데이터를 더하고, 그 결과를 다시 ACC에 저장한다.
- SUB(Subtraction): ACC에 있는 데이터와 메모리 주소 S에 있는 데이터를 빼고, 그 결과를 다시 ACC에 저장한다.
- JMP(Jump): 다음에 처리할 명령어의 주소를 S로 지정한다.
- JGE(Jump if Greator or Equal): ACC에 있는 데이터가 0보다 크거나 같다면, 다음에 처리할 명령어의 주소를 S로 지정한다.
- JNE(Jump if Not Equal): ACC에 있는 데이터가 0이 아니라면, 다음에 처리할 명령어의 주소를 S로 지정한다.
- STP(Stop): 멈춘다.
위와 같은 명령어들을 수행하기 위해 CPU에서는 Fetch Instruction, Instruction Decode, Operand Fetch, Execution Instruction, Write Back와 같은 단계들을 거쳐야 한다. 이러한 단계에 대해 자세히 설명하면 다음과 같다.
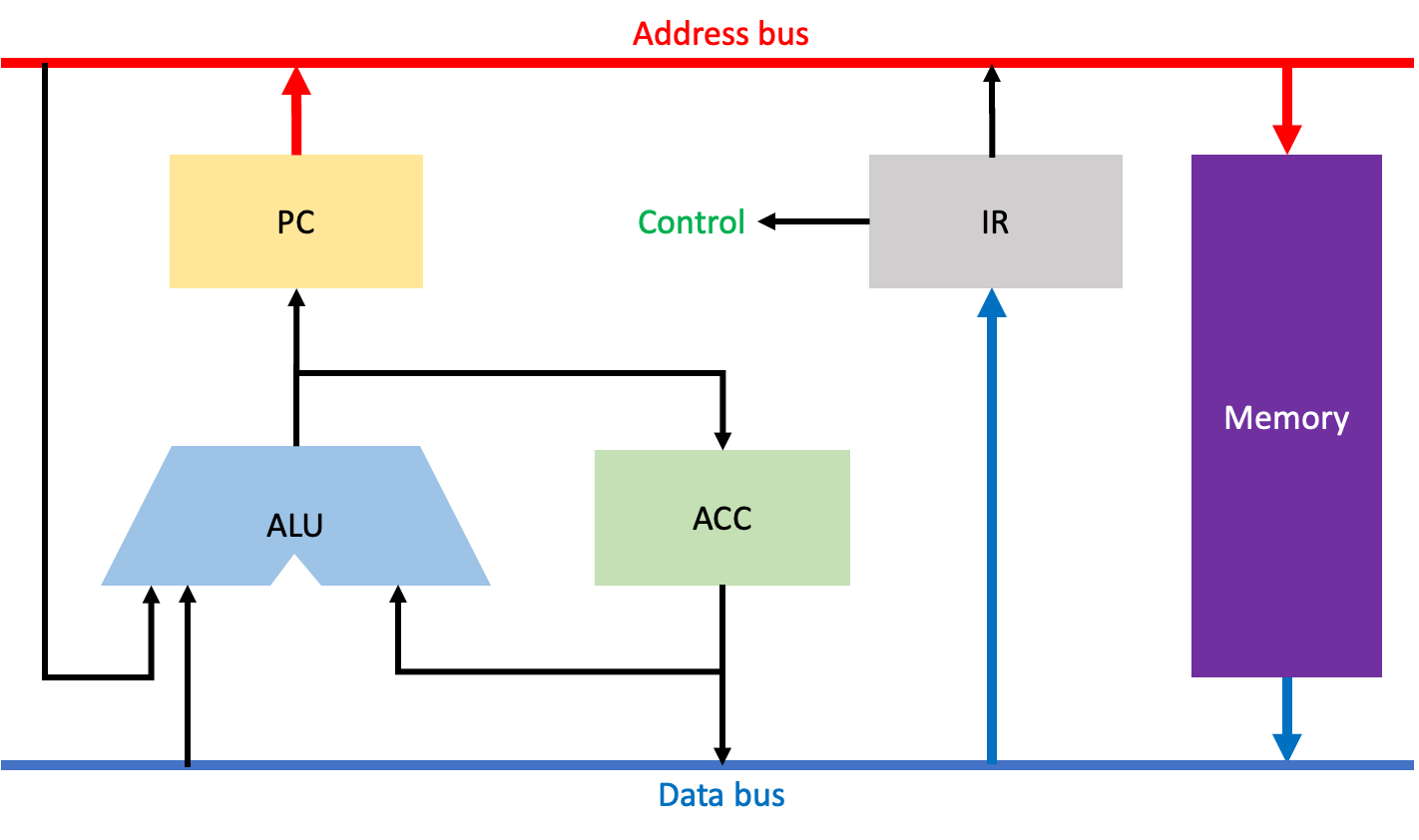
Fetch Instruction 과정이다. 이 과정은 PC에 지정된 주소에 있는 Instruction을 IR에 저장하는 단계로, 모든 CPU 명령어를 수행할 때 반드시 거쳐야 하는 단계이다.
주소버스를 통해 PC에 저장되어 있던 주소값이 메모리에 도달하고, 데이터버스를 통해 해당 주소에 존재하는 명령어를 IR로 가져와 저장한다.
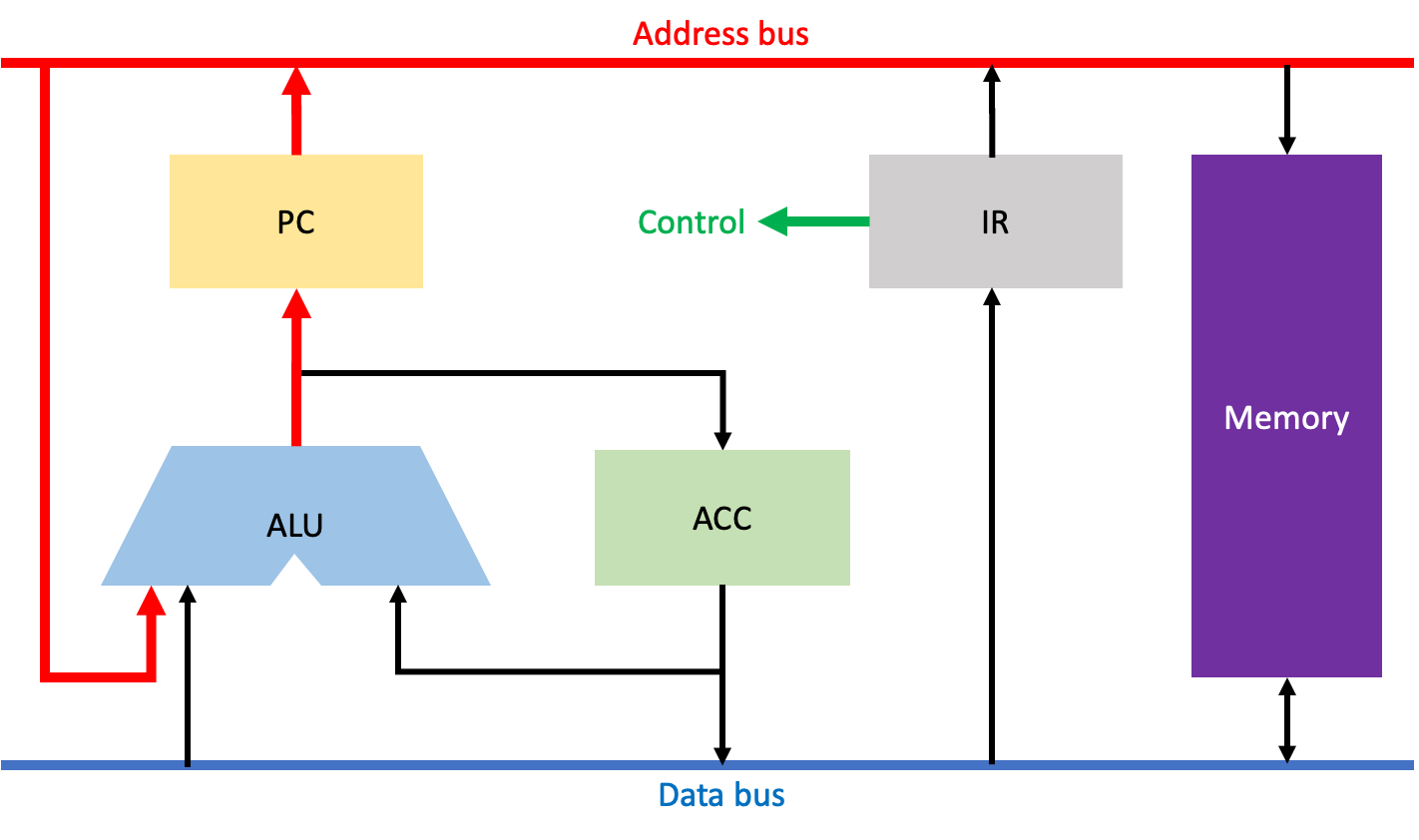
Instructoin Decode 과정이다. 이 과정은 IR에 저장된 명령어의 OP코드를 해석하고, PC에 지정된 주소를 +1 연산 해주는 단계다. 이러한 Instruction Decode 단계 또한 모든 CPU 명령어를 수행하기 위해 반드시 필요한 단계이다.
먼저 IR에 저장된 명령어의 OP코드를 해석하고, 그 결과를 제어 유닛에 전달한다. 그리고 주소버스를 통해 PC에서 현재 주소값을 가져와 ALU로 전달하고, ALU에서 +1 연산한 결과값을 다시 PC에 저장한다.
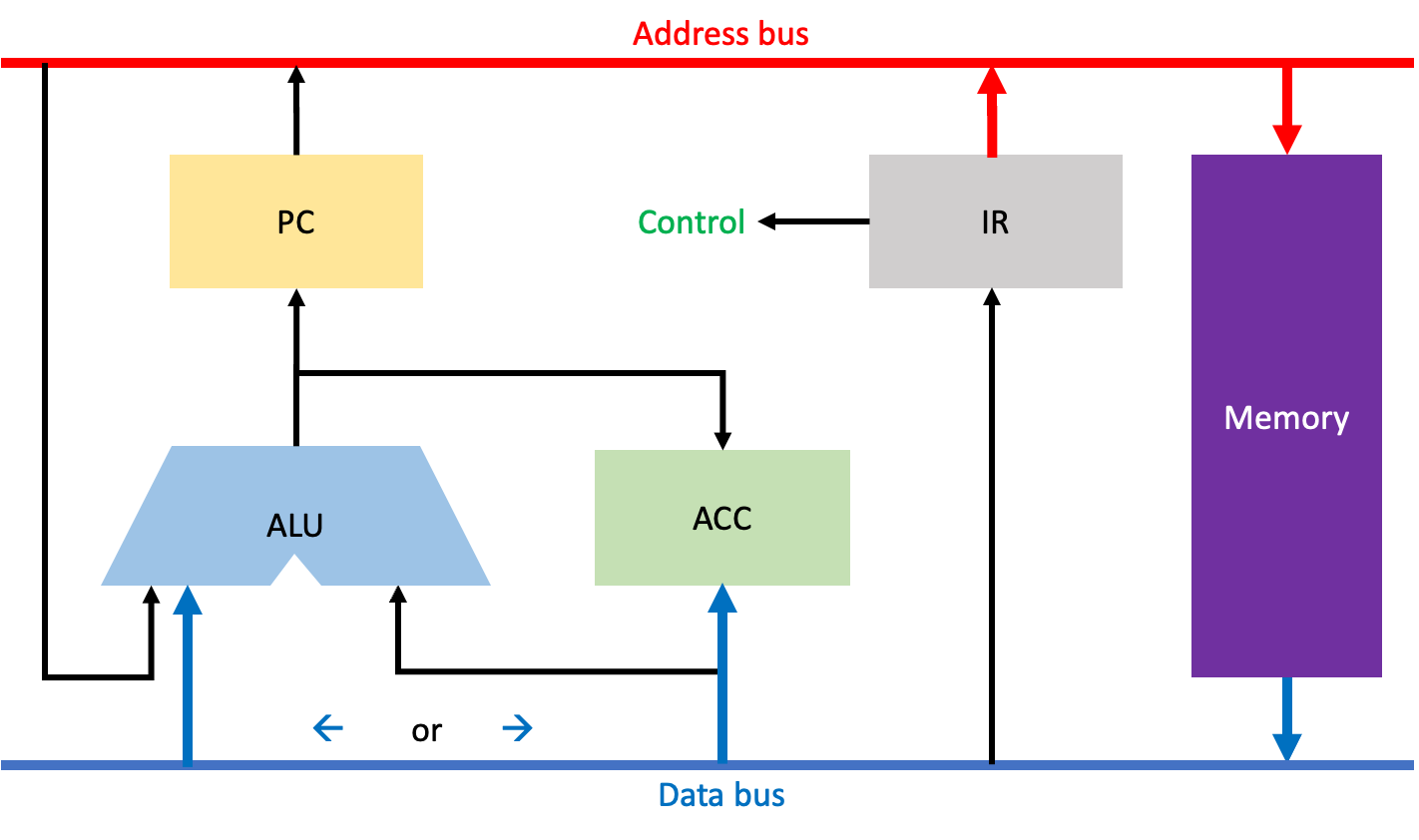
Operand Fetch과정이다. 이 과정은 IR에 저장된 명령어의 주소코드를 가지고 메모리로부터 해당 주소에 저장된 데이터를 가져오는 단계이다.
이 단계는 어떤 OP코드인지에 따라 다른 작업을 수행하지만, 우선 공통적으로 주소버스를 통해 IR에 저장된 명령어의 주소코드에 저장된 주소를 메모리에 전달한다.
다음으로 LDA명령어와 같이 단순히 메모리로부터 데이터를 가져와 ACC에 저장하는 경우에는, 데이터버스를 통해 메모리 내 해당 주소에 저장된 데이터를 ACC로 가져와 저장한다.
혹은 추후에 ADD명령어와 같이 ALU를 이용한 연산이 필요할 경우에는, 데이터버스를 통해 메모리 내 해당 주소에 저장된 데이터를 ALU에 전달하기도 한다.
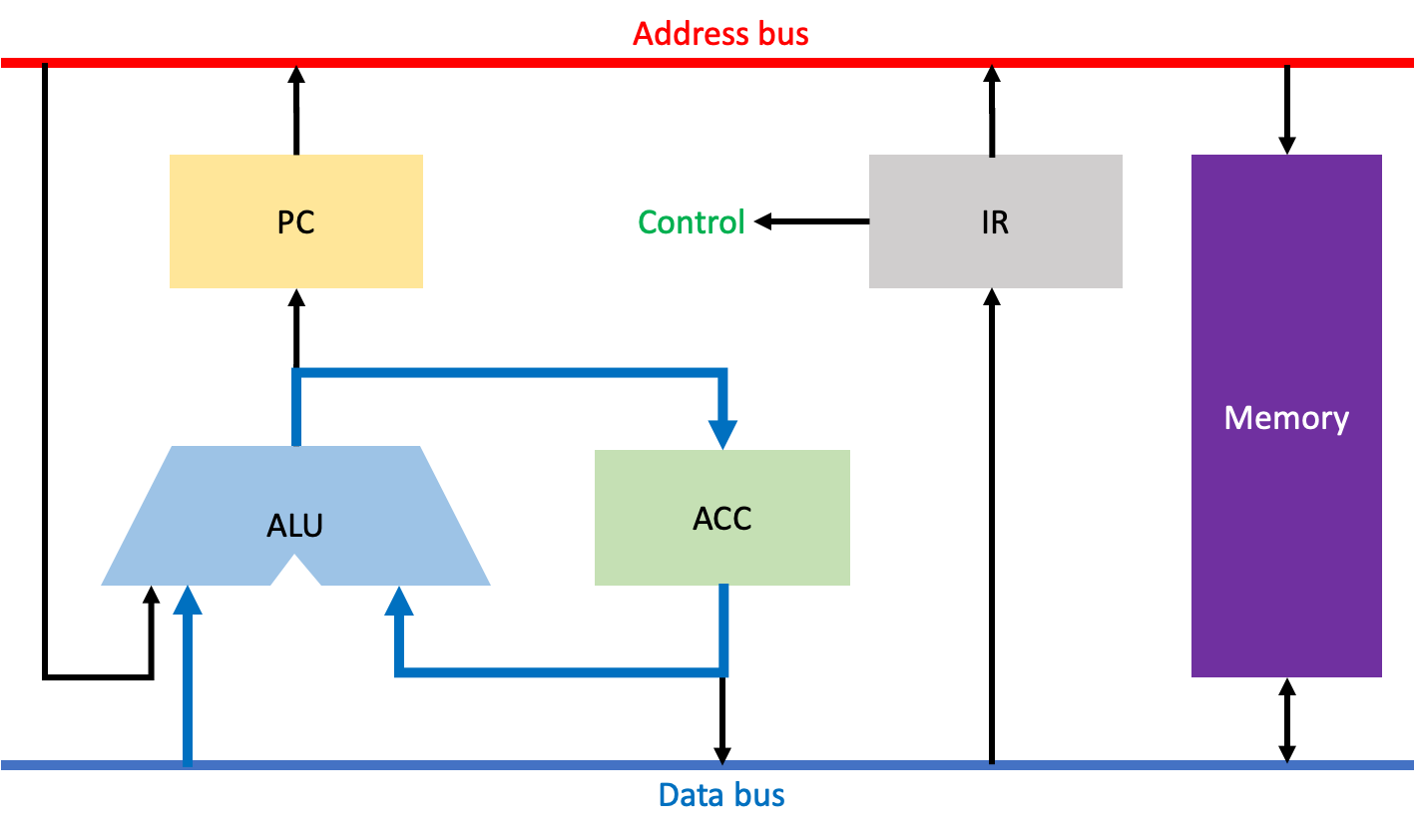
Execute Instruction 과정이다. 이 과정은 ALU를 통해 실제로 연산하는 과정이다.
이전 Operand Fetch 과정에서 주소버스를 통해 메모리로부터 가져와 ALU와 ACC에 저장한 데이터를 연산하고, 그 결과를 다시 ACC에 저장한다.
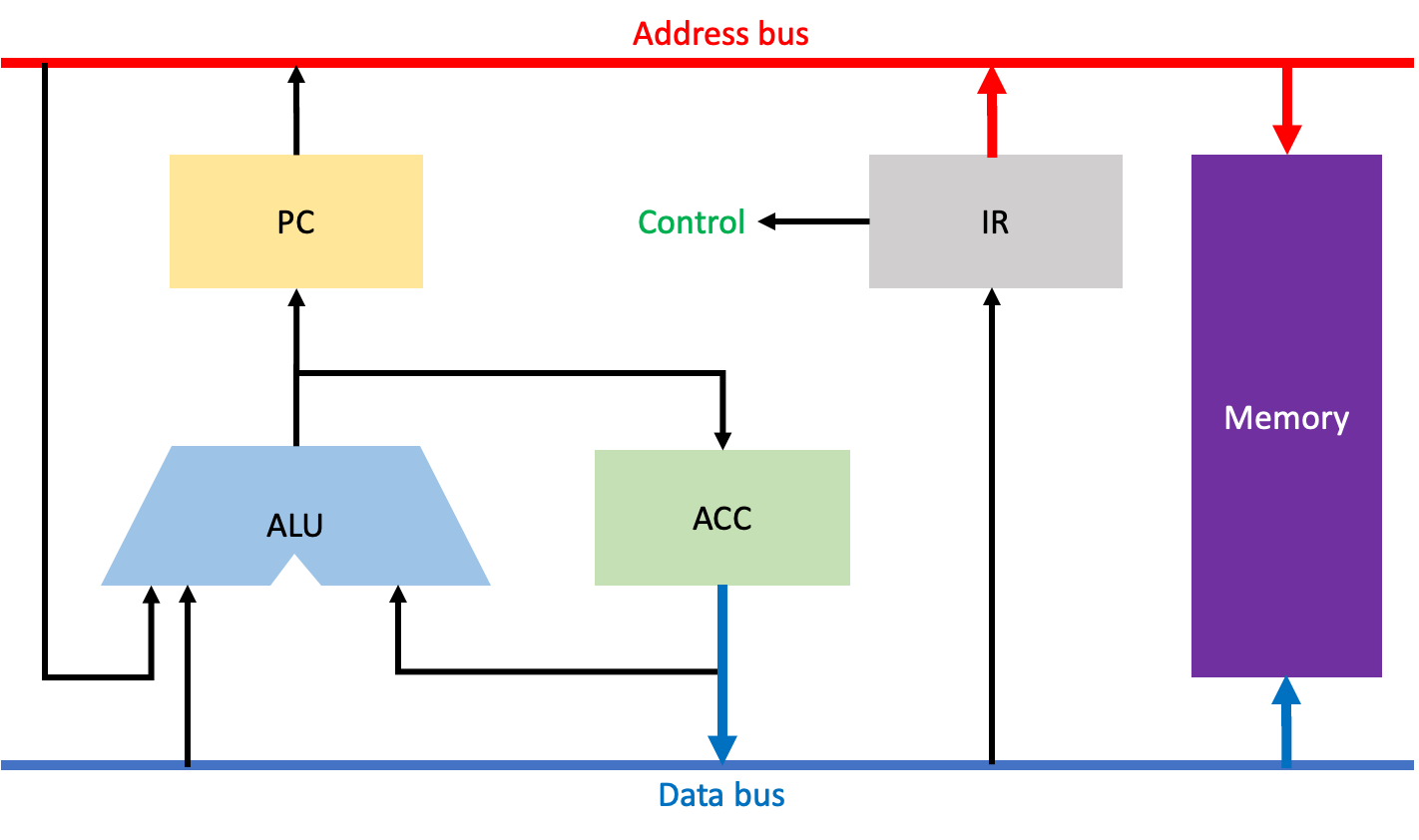
마지막으로 Write Back 과정이다. 이 과정은 STO(Store) 명령어에만 존재하는 단계이다.
주소버스를 통해 IR에 저장된 명령어의 주소코드 내 주소값을 메모리에 전달하여 해당 공간을 확보한다. 그리고 데이터버스를 통해 ACC에 저장된 데이터를 메모리로 전달하여 확보된 공간에 저장한다.
위 과정들 중 Fetch Instruction과 Instruction Decode 과정을 제외한 나머지 단계들은 CPU 명령어에 따라 필요할 수도 있고, 아닐 수도 있다.
그리고 각 과정 당 소요되는 시간은 한 클럭이라고 가정한다. 즉, 1Ghz에서의 한 클럭은 1나노초로, 10억분의 1초가 걸린다고 가정한다.
참고로, 위 과정 중에서 메모리로부터 정보를 읽어오는 시간이 가장 많이 걸린다고 한다.
Parallelism
파이프라이닝(Pipelining)
파이프라이닝은 명령어 처리 과정을 중, 겹치지 않는 작업들은 각각 따로 실행되도록 하여 병렬성을 높이고 결과적으로 작업 효율을 향상시키는 기법이다. 이러한 파이프라이닝의 가장 기본적인 전략은 나의 앞 작업이 그 다음 단계로 넘어가면, 원래 나의 앞 작업이 수행하던 단계는 비게 된다. 이러한 빈 자리의 작업을 내가 수행함으로 쉬지 않고 일하는 것이다.
파이프라이닝에서 수행하는 단계에는 FI(Fetch Instruction), DI(Decode Instruction), EI(Execute Instruction), WB(Write Back)이 있다.
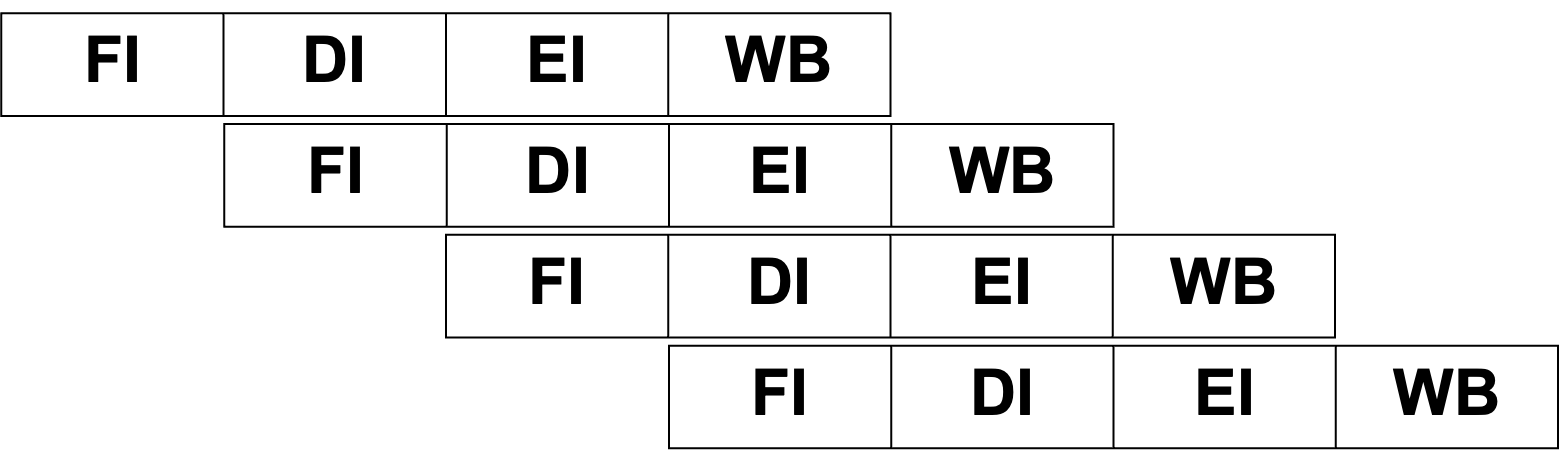
그리고 위와 같이 명령어 수행 과정에서 각 단계를 한번만 중첩하는 기술을 단일 파이프라인(Sindle Pipeline)이라고 한다.
이러한 파이프라인에는 몇몇 문제점이 있다. 먼저 파이프라인의 근본적인 문제에는 모든 명령어들이 파이프라이닝에서 수행하는 단계들을 전부 통과하지 않지만, 구조의 단순화를 위해 4단계의 파이프라인을 통과해야 해서 어떻게 보면 비효율적일 수 있다는 점과, Clock Speed가 율속단계에 맞춰진다는 점이다.

여기서 율속단계란, 모든 작업 중 가장 시간이 많이 소요되는 단계를 말한다. 율속단계에 맞춘다는 이야기를 쉽게 설명하자면, 식당에서 음식을 담는 예를 들 수 있다.
위 사진과 같이 사람들이 한 줄로 서서 음식을 담을 때, 각 음식 별로 담는 데에 소요되는 시간이 다 다를 수 있다. 그러나 음식을 담는 작업이 빈틈없이 실행된다는 가정을 한다면, 결국 모든 사람들은 가장 오래 소요되는 시간인 8초만큼 기다려야 하기 때문에 전체적으로 다음 음식을 담기까지 소요되는 시간은 8초로 통일된다는 이야기이다.
그리고 파이프라인의 근본적인 문제점 외에 단일 파이프라인의 문제점에는 구조적 문제, 데이터 문제, 제어 문제가 존재한다.
구조적 문제
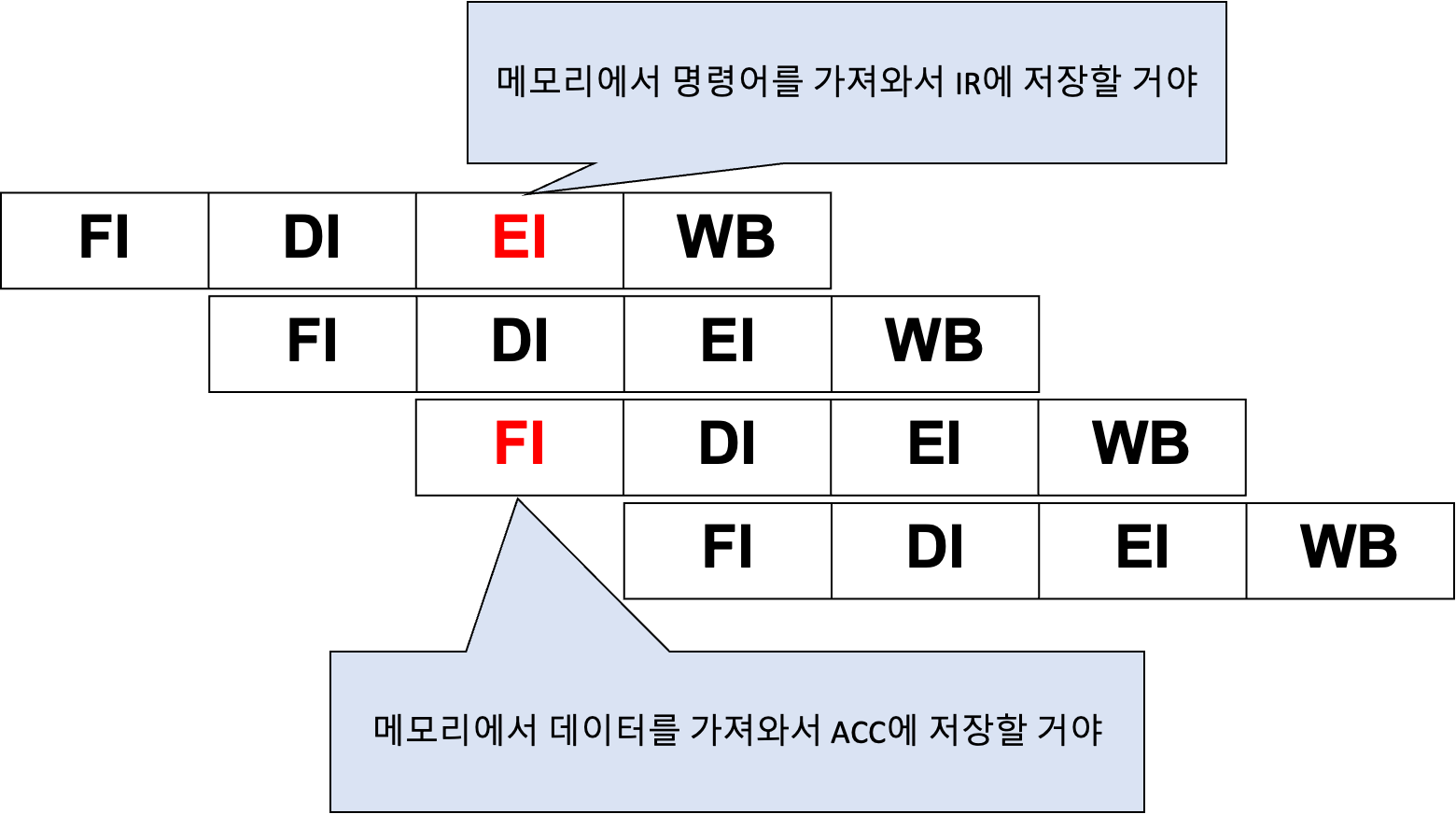
구조적 문제(해저드)는 서로 다른 파이프라인 단계(FI, EI)가 메모리장치에 접근하려 할 때 발생하는 문제다. 특히 폰 노이만 구조에서는 명령어를 저장하는 장치와 데이터를 저장하는 장치가 분리되어있지 않기 때문에 FI 단계와 EI 단계가 겹칠 경우 구조적 문제가 발생한다.
이러한 구조적 문제는 지연시키거나, 명령어 메모리와 데이터 메모리를 분리해 관리하는 하버드구조(Havard Architecture)를 도입하여 해결할 수 있다.
데이터 문제
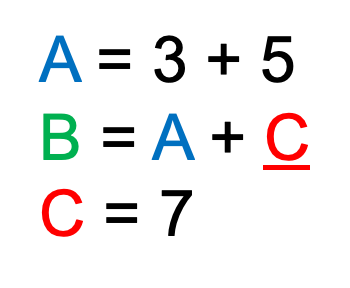
데이터 문제(해저드)는 이전 명령어의 실행 결과를 저장하기 전에 다음 명령어가 실행 결과를 사용하려고 할 때 발생하는 데이터 의존성 문제다. 이를 극단적으로 설명하자면, 위 식을 순차적으로 실행해야 하는 상황에서 C가 정의되기 전에 B를 계산하려고 할 때 발생하는 오류이다.
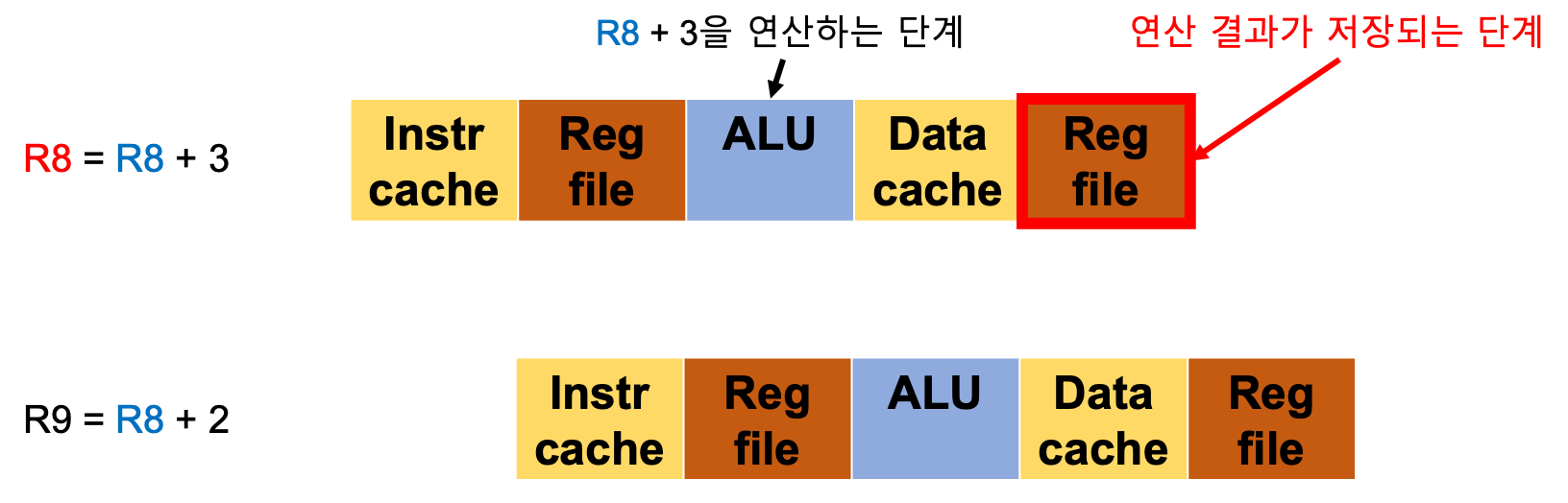
이를 보다 자세히 설명하자면, 위와 같이 기존에 있던 R8의 데이터와 3을 더한 결과를 R8에 저장하라는 명령이 있고, 그 다음에 R8의 데이터와 2를 더한 결과를 R9에 저장하라는 명령이 있다고 하자.
이때 R8은 기존에 있던 R8의 데이터이고, R8은 연산 과정을 통해 갱신된 R8을 의미한다.
그러나, ALU에서 R8 + 3의 연산이 수행되더라도 결과값이 저장되는 단계는 마지막 Reg file로 표시된 WB단계이다. 때문에 R9값을 구하는 명령어에서 R8을 불러오면 갱신된 결과가 아닌 기존에 있던 R8의 데이터를 가져오게 된다. 이러한 문제가 데이터 문제이다.
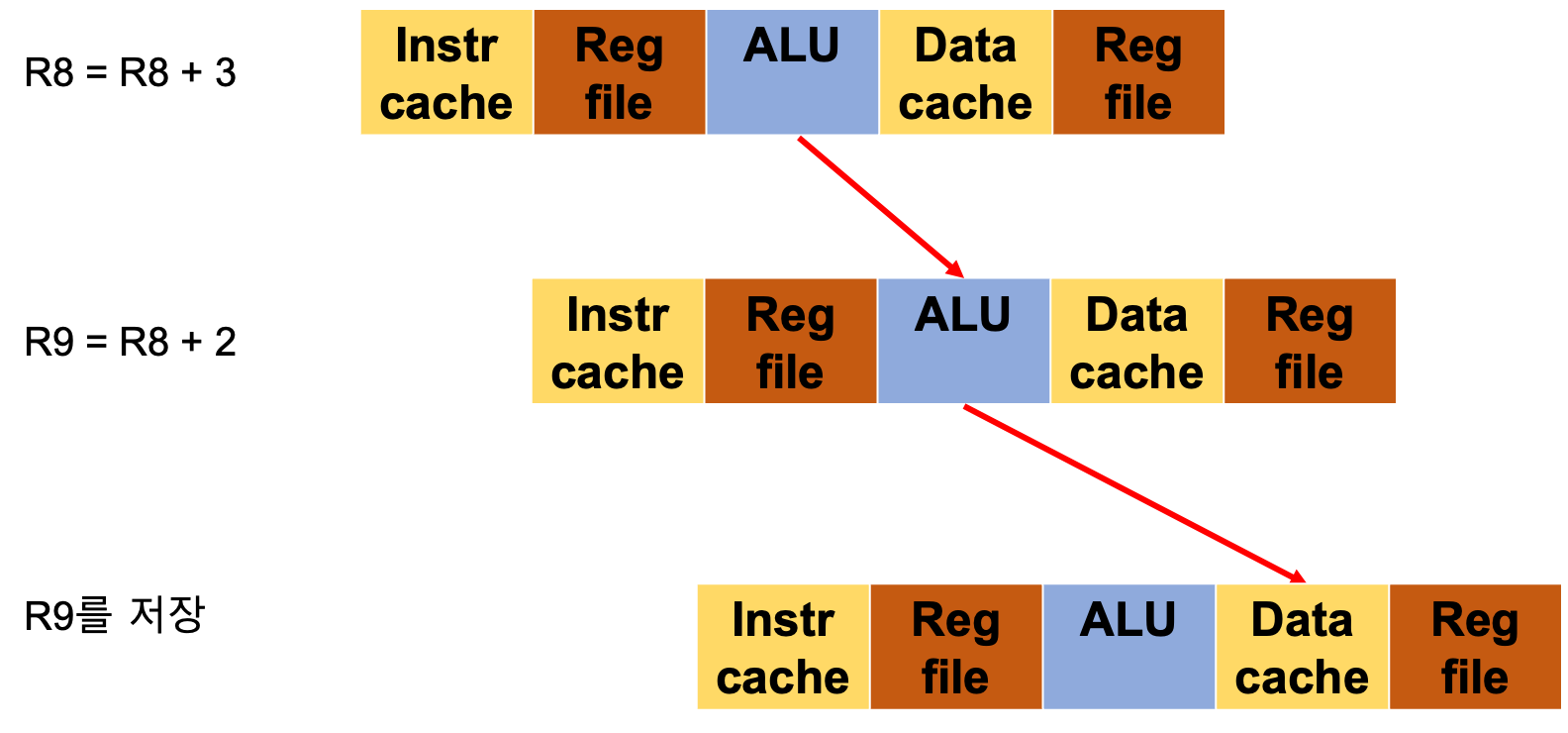
이러한 문제는 연산 값이 저장될 때까지 지연하거나, 위와 같은 데이터 포워딩 기법을 통해 해결할 수 있다.
데이터 포워딩이란 이전 명령어에서 처리된 결과 값을 바로 다음 명령어에서 사용할 수 있도록 하는 기법이다. 이때 결과 값을 보내는 경로는 명령어에 따라 다르다.
ALU 연산을 필요로 하는 명령어의 경우, 결과 값을 다음 명령어의 ALU로 전달함으로 데이터 문제를 해결했다.
그러나 ALU 연산을 필요로 하지 않고 메모리에 저장하는 명령어의 경우, 결과 값을 다음 명령어의 Data cache에 전달함으로 데이터 문제를 해결했다.
제어 문제
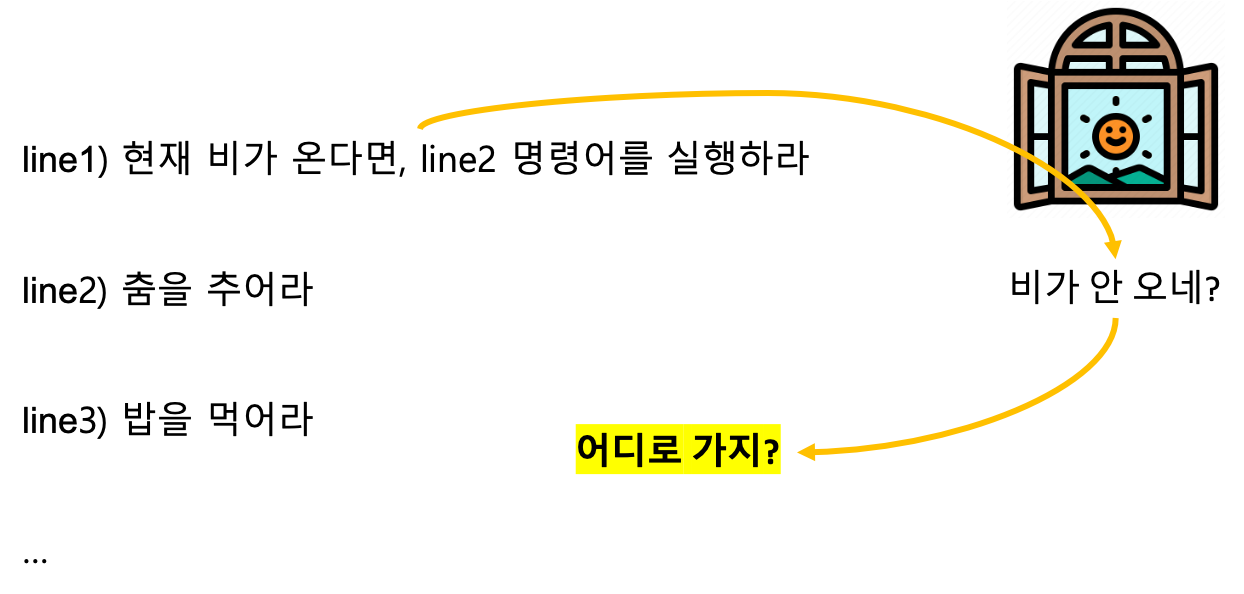
대표적인 제어 문제(해저드)는 Jump 명령어가 포함된 분기 상황, 특히 조건 분기 상황에서 다음으로 수행할 명령어를 적절히 고르지 못할 때 발생하는 문제다.
이러한 제어 문제는 분기 예측방식(Branch Prediction)이나 지연 분기방식(수업에서는 Delayed Instruction로 설명)을 수행하여 해결할 수 있다.
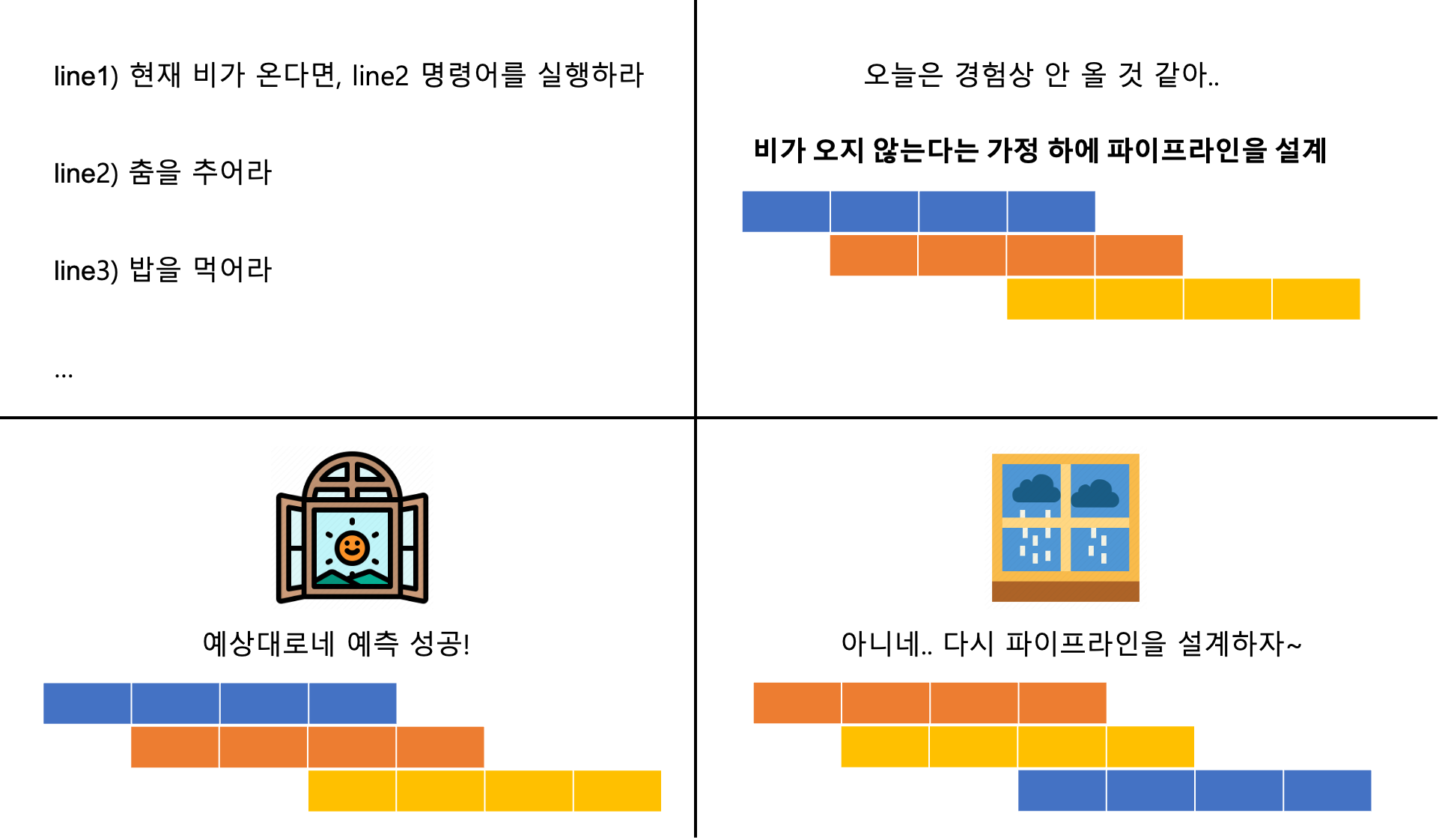
위 그림은 분기 예측(Branch Pradiction)을 통해 제어 문제를 해결하는 과정이다. 분기 예측방식은 해당 분기가 발생할지 여부를 여러가지 경험을 통해 예측한다. 그리고 예측한 결과에 따른 파이프라인을 미리 설계한 후, 예측이 맞다면 미리 설계한 파이프라인대로 작업을 수행하면 되므로 제어 문제가 해결된다. 만약 예측이 틀린다면 파이프라인을 다시 설계한다. 결국 예측이 틀릴 경우에는 제어 문제가 해결되지 않았다고 볼 수 있다.
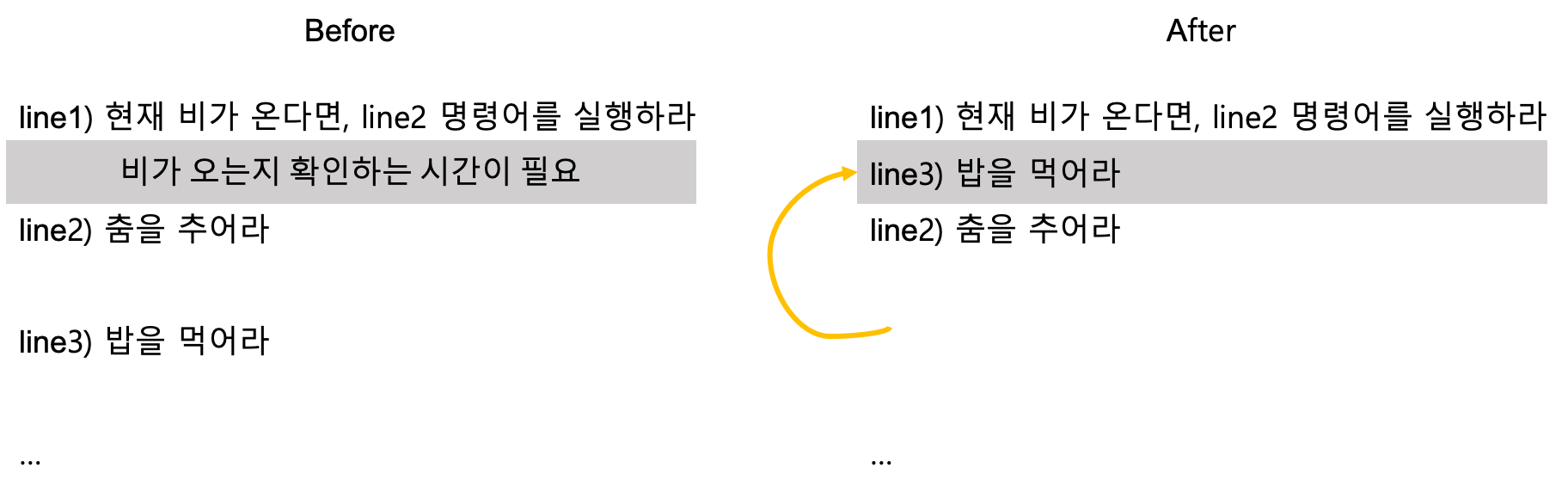
위 그림은 지연 분기를 통해 제어 문제를 해결하는 과정이다. 지연 분기는 '조건 분기'에서만 사용이 가능한 방식인데, 조건문을 비교하는 데에 소요되는 공백 시간에 분기와 상관없이 수행되는 명령어를 수행하는 방식이다. 이를 통해 어차피 존재해야 했던 공백시간을 줄임으로 제어 문제를 해결할 수 있다.
참고로, 그냥 조건에 맞춰서 분기할 때마다 파이프라인을 설계하면 되는 문제 아니냐는 의문을 가질 수 있다. 실제로 분기 명령어로 인해 중간에 있던 파이프라인을 건너 뛰게 되면 해당 파이프라인들은 다 날아가게 되는데 이러한 현상을 'Pipelining flush'라고 한다. 이러한 현상이 많이 일어나면 처리 속도가 매우 느려진다. 때문에 분기 명령어가 많을 수록 속도는 느려지게 된다. 결국 'Pipelining flush'를 피하기 위해서는 분기 예측은 필수적이다.
슈퍼 파이프라인
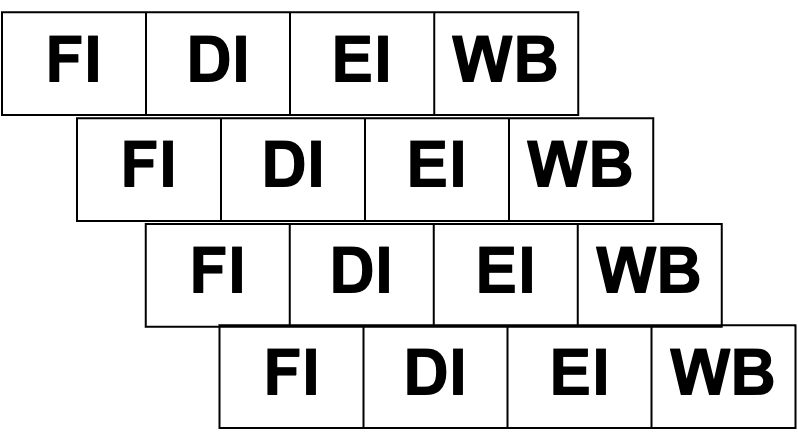
슈퍼 파이프라인은 하나의 파이프라인을 여러 부분으로 나눈 것이다. 이러한 구조는 구조 자체가 슈퍼스칼라보다 단순하고, 비교적 적은 부품을 사용한다는 장점이 있다. 또한 단계를 세분화했기 때문에 Clock Cycle Time이 줄어들어, Clock Rate가 높아진다. 그러나 Clock Rate이 너무 높아지면 단계를 세분화하기 어려워진다.
슈퍼 스칼라
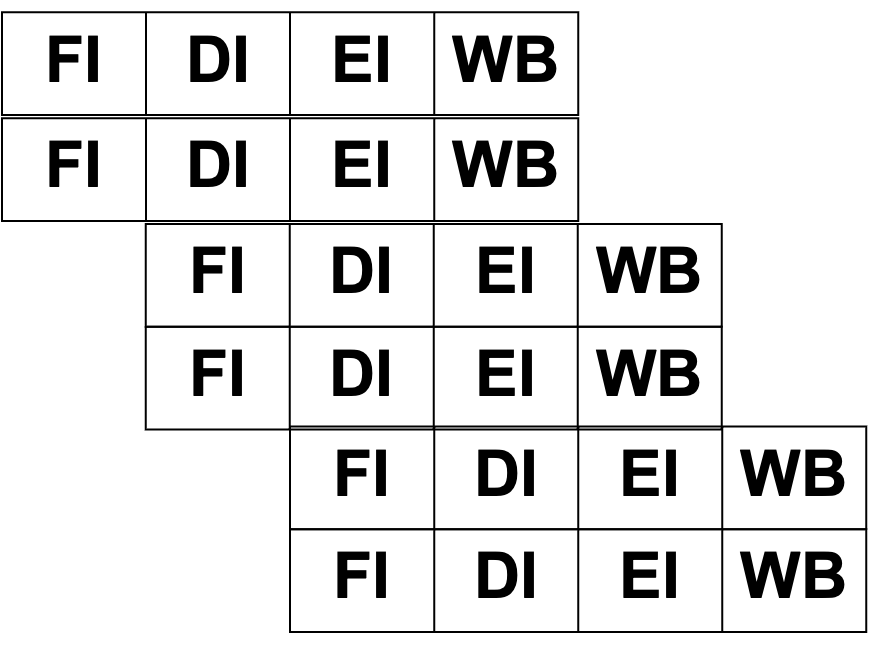
슈퍼 스칼라는 CPU 내에 여러 파이프라인을 두어 매 사이클마다 여러 명령어를 동시에 수행하는 기술이다.
슈퍼 파이프라인 - 슈퍼 스칼라
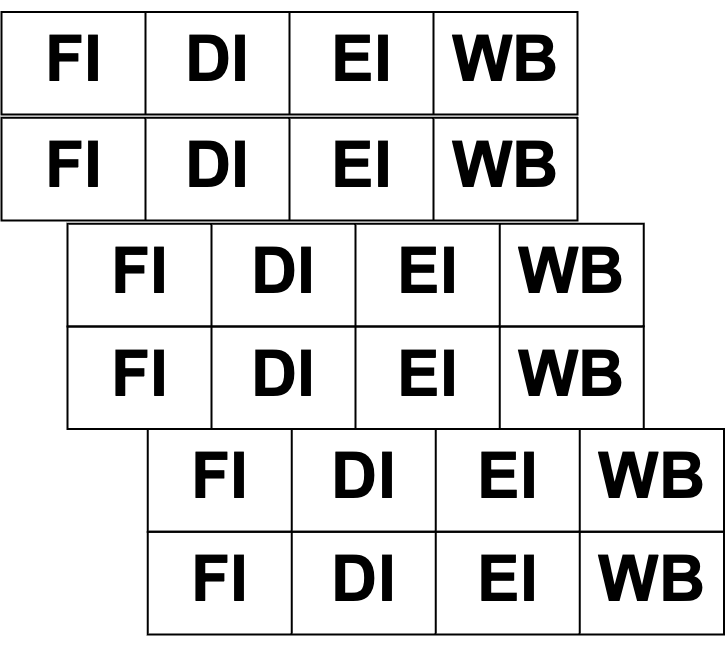
위 둘을 합친 슈퍼 파이프라인 - 슈퍼 스칼라 기법이다. 요즘 가장 많이 쓰이고 있다고 한다.
이외에도 VLIW라는 방식도 쓰이고 있다고 하는데 이에 대한 설명은 참고 정도만 하면 좋을 것 같다.
VLIW는 Very Long Instruction Word(아주 긴 명령어 단어)의 약자로, 하나의 명령어에 여러 개의 작은 명령어들을 결합하여 처리하는 방식이다. VLIW 프로세서는 하나의 명령어에 여러 개의 연산을 포함시켜 병렬처리를 가능하게 한다.
VLIW 아키텍처는 하나의 명령어에 대해 매우 복잡한 디코딩을 필요로 하지 않기 때문에 전체 명령어 스트림을 빠르게 처리할 수 있다. 또한, 명령어 내부의 작은 명령어들이 여러 개의 기능 유닛에서 병렬적으로 수행될 수 있어 실행 속도를 높일 수 있다.
VLIW는 대규모 데이터 처리나 멀티미디어 애플리케이션과 같이 복잡한 연산을 수행하는 애플리케이션에 특히 유용하다
'대학교 공부 > 컴퓨터시스템 (2023)' 카테고리의 다른 글
| 6주차 - Cache(캐시), Mapping Function(사상 방식), Replacement Algorithms(교체 알고리즘), Write Policy (0) | 2023.04.10 |
|---|---|
| 4주차 - Instruction Execution Unit, 주소 지정 방식, Hard wired & Micro programming (0) | 2023.04.10 |
| 3주차 - 최상위 관점에서의 CPU요소, 폰노이만&하버드 구조, CISC&RISC (0) | 2023.03.25 |
| 2주차 - 컴퓨터 시스템 설명 (0) | 2023.03.17 |